


A quick search online on Spark will leave you swimming in documentation, online courses and a plethora of other resources. From my experience, the majority of these either assumed you knew too much about distributed computing (like assuming I knew what distributed computing meant for example), or they gave high-level or background information without helping me understand how to actually implement anything in Spark.
With that in mind, here I tried my best to either explain the concept, or direct you somewhere else with an explanation, all with the goal of getting you writing Spark code as quickly as possible.
Let’s first learn some key terminologies so that we will not feel alien when dive into the topic or reading the external links which are definitely loaded with these jargons.
What we’ll Learn?
- Enough terminology and concepts to be able to read other Spark resources without being confused.
- A relatively painless way to get PySpark running on the computer.
- How to get started with data exploration in PySpark.
- Building and evaluating a basic linear regression model in PySpark.
- Helpful external resources for the majority of material covered here.
What is Spark?
If we try to consolidate all the google results of the above question then it something sounds like this “Spark is a general-purpose distributed data processing engine”.
Let’s try to understand each pieces of the above definition.
What do we mean by distributed data?
When datasets get too big, or when new data comes in too fast, it can become too much for a single computer to handle. This is where distributed computing comes in. Instead of trying to process a huge dataset on one computer, these tasks can be divided between multiple computers that communicate with each other to produce the output. When Spark says it has to do with distributed data, this means that it is designed to deal with very large datasets and to process them on a distributed computing system. In a distributed computing system, each individual computer is called a node and the collection of all of them is called a cluster.
If you are interested to know more about distributed computing. Read here
What is a processing engine?
As the name says the processing engine or processing framework does the data processing task. We can best explain it by doing a comparison. We know Hadoop is also deals with bigdata and distributed computing. It also has a processing engine called MapReduce which has its own way of optimizing the processing tasks on different nodes. One of Spark processing engine’s advantage is that it can be used on its own or we can replace it MapReduce while using all other Hadoop features.
To know more about the framework comparisons, you can refer this Digital Ocean’s community article.
General Purpose
Spark supports Scala, Python, Java, R, and SQL. It has a dedicated SQL module, it is able to process streamed data in real-time, and it has both a machine learning library and graph computation engine built on top of it. All these reasons contribute to why Spark has become one of the most popular processing engines in the realm of Big Data.
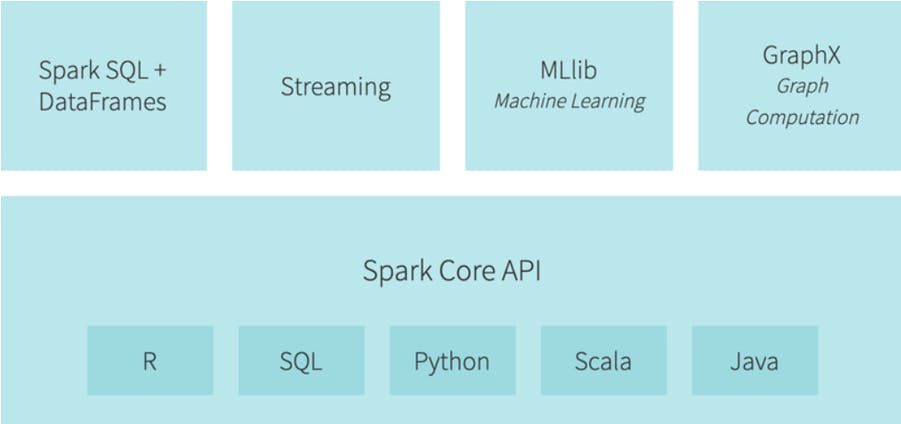
Now let’s try to debunk some distributed computing related key-terms.
Partitioned Data
We now know that Spark framework runs the data processing task on multiple nodes that means we have to send the well optimized data means portioned data to each node so they can be processed by those tasks.
For further study on data portioning this article could be a good choice.
Fault Tolerance
Fault tolerance refers to a distributed system’s ability to continue working properly even when a failure occurs. A failure could be a node bursting into flames for example, or just a communication breakdown between nodes. Fault tolerance in Spark revolves around Spark’s RDDs (will discuss it later). Basically, the way data storage is handled in Spark allows Spark programs to function properly despite occurrences of failure.
Lazy Evaluation
Here evaluation refers to the code compilation. The strict compiler sequentially evaluates each expression it come across while the lazy compiler just sit idle until its been told to give result, once asked it started evaluating all the expressions at once.
As it compiles code, it keeps track of everything it will eventually have to evaluate (in Spark this kind of evaluation log, so to speak, is called a lineage graph), and then whenever it is prompted to return something, it performs evaluations according to what it has in its evaluation log. This is useful because it makes programs more efficient as the compiler doesn’t have to evaluate anything that isn’t actually used.
A worth reading article for basic understanding on the Lazy compilation. Read here
Now lets understand some Spark related key terms.
Spark RDD
RDD stands for Resilient Distributed Dataset. It is the heart of the Spark. Its nothing but a collection of immutable objects that split across cluster. Means its collection of record which holds values, tuples, or other objects and they are partitioned so that can be processed on distributed systems. These objects are impossible to alter.
That basically sums up its acronym: they are resilient due to their immutability and lineage graphs, they can be distributed due to their partitions, and they are datasets because, well, they hold data. A crucial thing to note is that RDDs do not have a schema, which means that they do not have a columnar structure. Records are just recorded row-by-row, and are displayed similar to a list.
Spark DataFrames
Not to be confused with Pandas DataFrames, as they are distinct, Spark DataFrame have all of the features of RDDs but also have a schema. This will make them our data structure of choice for getting started with PySpark.
Spark DataSets
Datasets are another type of data structures like DataFrames. These are similar to DataFrames but are strongly-typed, meaning the type is specified while the creating the DataSet and is not inferred from the type of records stored in it. This means DataSets are not used in PySpark because Python is a dynamically-typed language.
There is this nice article on the above three Spark API’s comparisons.
Transformations
Transformations are lazy operations which creates RDDs. Remember RDDs are immutable objects so we can’t alter them but we can crate a new ones. Transformations take an RDD as an input and perform some function on them based on what Transformation is being called, and outputs one or more RDDs. It doesn’t actually build any new RDDs, but rather constructs a chain of hypothetical RDDs that would result from those Transformations which will only be evaluated once an Action is called. This chain of hypothetical, or “child”, RDDs, all connected logically back to the original “parent” RDD, is what a lineage graph is.
Actions
An Action is any RDD operation that does not produce an RDD as an output. Some examples of common Actions are doing a count of the data, or finding the max or min, or returning the first element of an RDD, etc. As was mentioned before, an Action is the cue to the compiler to evaluate the lineage graph and return the value specified by the Action.
Lineage Graph
It is also called the Logical Execution Plan. The compiler starts with the earliest RDD which is not dependent on any other RDDs and follow a logical chain of hypothetical RDDs created by Transformations until it ends with a RDD that an Action is called on. This feature is primarily what drives Spark’s fault tolerance. If a node fails for some reason, all the information about what that node was supposed to be doing is stored in the lineage graph, which can be replicated elsewhere.
An example of Lineage Graph where r00, r01 are parent RDDs, r20 is final RDD. The Lineage graphs are directed acyclic graph types.
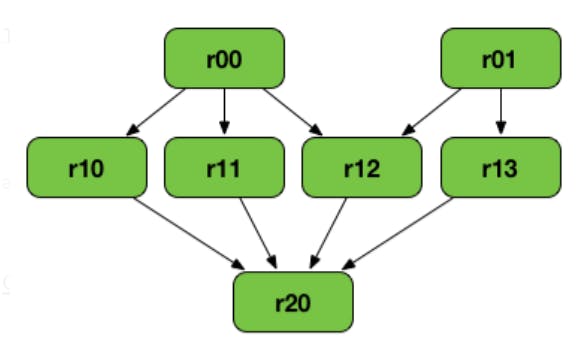
For more reading on RDD Lineage.
Spark Applications and Jobs
There is a lot of nitty gritty when it comes to how a processing engine like Spark actually executes processing tasks on a distributed system. We will try to understand the basic which we help us to understand the working execution of certain Spark code.
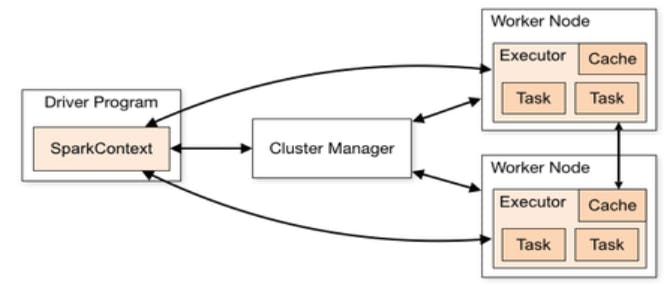
In Spark, when an item of processing has to be done, there is a “driver” process that converts the user’s code into multiple tasks. There there is another process called “executor” which responsible for executing these tasks on individual nodes on a cluster. Each driver process has a set of executors that it has access to in order to run tasks.
A Spark application is a user-built program that consists of a driver and that driver’s associated executors. A Spark job is task or set of tasks to be executed with executor processes, as directed by the driver and a job is triggered by the calling of a RDD Action.
A simplified visualization of Spark Architecture.
Further reading on Spark Cluster.
Further reading on Spark Application.
We have made it through all the Spark related key terminologies and some core concepts. In the next chapter we will know about Spark installations and do some coding with PySpark.