

Machine Learning algorithms are able to train themselves to recognize patterns in data and make predictions by first analyzing large volumes of sample data points that have been labelled with the “answer” the algorithm is trying to guess.
Image recognition programs are a good example of this. If you want to develop a program that can distinguish between cars and trucks, you need to train it on a dataset filled with pictures of vehicles labelled “car” or “truck.” The same is true for fraud detection programs in finance. They need to train on a dataset filled with transactions that have been labelled “normal” and “fraudulent” so they can understand the differences between the two. This is called supervised machine leaning where having some amount of training data is a prerequisite for machine learning.
But in real world we are not always that lucky to get labelled data all time. Often, we need to create models with unlabeled datasets. Adding labels to unlabeled datasets is a time-intensive process, after all, that may require extensive human labor before you’re even able to get started. That’s where active learning comes into play. With active learning, a ML algorithm can scan unlabeled training data and identify only the most useful data points for analysis. The program can then actively query either a labelled dataset (like one that has all the “car or truck” answers) or a human annotator (who simply tells the computer if the image in question shows a car or truck). And since the algorithm is only selecting the data points it needs for training purposes, the total number of data points required for analysis can often be much lower than in normal supervised learning.
Where is it useful?
Active learning especially useful for natural language processing, as building NLP models requires training datasets that have been tagged to indicate parts of speech, named entities, etc. Getting datasets that both feature this tagging and contain enough unique data points could be a challenge. Active learning has also been useful for medical imaging and other instances in which there’s a limited amount of data that a human annotate can label as necessary to help the algorithm.
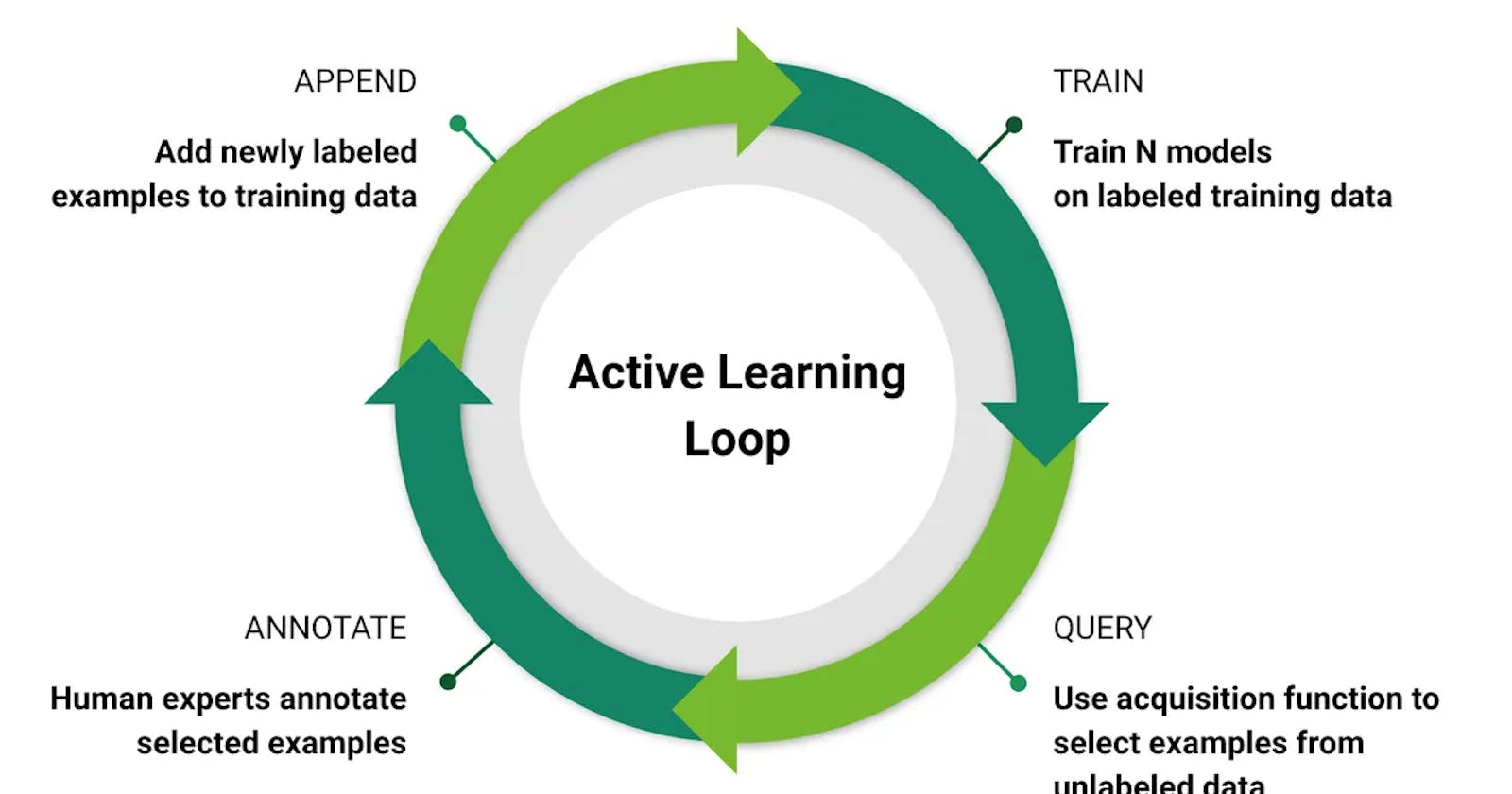
How it is used?
Active learning can be implemented using any of the below methods
A stream-based selective sampling approach, in which remaining data points are assessed one-by-one, and every time the algorithm identifies a sufficiently beneficial data point it requests a label for it. This technique can require considerable human labor.
A pool-based sampling approach, in which the entire dataset (or some fraction of it) is evaluated first so the algorithm can see which data points will be most beneficial for model development. This approach is more efficient than stream-based selective sampling but does require a lot of computational power and memory.
A membership query synthesis approach, where the algorithm essentially generates its own hypothetical data points. This approach only applies to limited scenarios where generating accurate data points is plausible.
Active learning is one of the most exciting topics in data science today. We can interpreted the active learning as it is a form of semi-supervised machine learning that facilitates faster algorithm training by proactively identifying high-value data points in unlabeled datasets.
Hope you have liked the blog. Happy learning!